Protocol buffers provide a language-neutral, platform-neutral, extensible mechanism for serializing structured data in a forward-compatible and backward-compatible way. It’s like JSON, except it’s smaller and faster, and it generates native language bindings.
Protocol buffers are a combination of the definition language (created in .proto files), the code that the proto compiler generates to interface with data, language-specific runtime libraries, and the serialization format for data that is written to a file (or sent across a network connection).
使用Protocol Buffers的好处:
- 使用二进制来编码数据,数据更紧凑,数据传输更快、更高效
- 快速解析
- 在序列化数据方面,灵活,高效,支持丰富的数据类型
- 支持多种编程语言
- 通过自动生成的classes来优化功能
- 更好的兼容性
Protocol Buffers不适合的场景:
- Protocol Buffer倾向于假设完整的消息可以一次性加载到内存中。如果数据量超过MB级别,应该考虑不同的解决方案
- 同样的数据可能有不同的二进制序列化值。因此不能进行比较
- Message不能进行压缩
- 等等
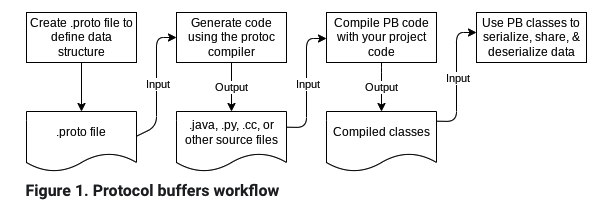
使用Protocol Buffers的工作流图:
Message编码
Message structure 提到,protocol buffer message是一系列键值对。消息的二进制版本仅仅使用字段的field_numberr作为key,每个字段的名称和声明的类型只能在解码端通过引用消息类型的定义(.proto文件)来确定。
当编码消息时,keys和values被拼接成字节流。当解码消息时,解析器能够跳过它无法识别的字段。这样,将新字段添加到消息中,不会破坏不了解该定义的老程序。因此,wire格式消息中每一对key-value的key实际上是两个值–proto文件中的字段编号+wireType提供的足够信息用来查找value的长度。
可用的wire类型如下:
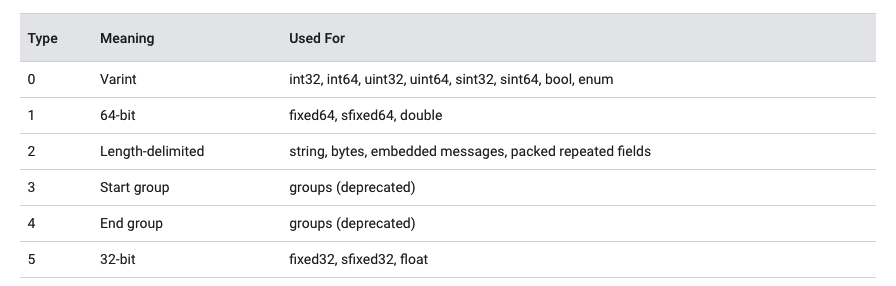
二进制消息中每个key是varint类型,值为:field_number <<3 | wire_type。简单地说,key的最后3位bit存储了wire_type。
pb在序列化和反序列化数据时,通过
field_number来定位field。
value的编码需要根据wire_type选择不同的编码算法,具体可参考:链接
当wire_type=2时,key-value格式将转换为key-length-value格式。
proto文件中field number可以是任意顺序,不影响消息的序列化。