分布式训练系统
分布式训练需要使用由多台服务器组成的计算集群(Computing Cluster)完成。而集群的架构也需要根据分布式系统、大语言模型结构、优化算法等综合因素进行设计。 分布式训练集群属于高性能计算集群(High Performance Computing Cluster,HPC),其目标是提供海量的计算能力。 在由高速网络组成的高性能计算上构建分布式训练系统,主要有两种常见架构: 参数服务器架构(Parameter Server,PS)和去中心化架构(Decentralized Network)。
我将分布式训练系统划分如下:
- 应用层:模型训练算法层
- 分布式算法层:多种并行算法策略
- 分布式计算架构:参数服务器架构、去中心化架构
- 基础设施层:高性能计算集群、基于k8s的分布式调度系统
- 硬件层:计算设备GPU/CPU等
分布式训练需要解决的问题
随着语言模型参数量和所需训练数据量的急速增长,单个机器上有限的资源已无法满足大语言模型训练的要求。
需要设计分布式训练(Distributed Training)系统来解决海量的计算和内存资源要求问题。在分布式训练系统环境下需要将一个模型训练任务拆分成多个子任务,并将子任务分发给多个计算设备,从而解决资源瓶颈。 但是如何才能利用包括数万计算加速芯片的集群,训练 模型参数量千亿甚至是万亿的大规模语言模型?这其中涉及到集群架构、并行策略、模型架构、内存优化、计算优化等一系列的技术。
随着分布式训练系统规模的增大,底层的分布式计算系统会出现一些新的问题:
- 系统的容灾能力不足:需要解决机器层面、容器Pod、训练算法进程异常带来的问题。
- 缺少弹性算力感知和动态训练扩缩容机制
- 集群资源配置/调度机制不灵活:需要考虑分布式训练任务的特性
这些问题的关键在于:分布式训练系统的弹性。
而弹性训练,就是指让训练任务能够在运行时动态地调整参与计算的实例数量。这使得训练更加灵活,同时可以配合集群的负载进行更好的扩缩容和调度。具体可以总结为三大块的能力:
- 训练规模弹性改变:这里主要指的是弹性改变训练的 Worker 数目,扩容增加 Worker 数量以提升训练速度,缩容减少 Worker 数量以腾出部分集群资源;
- 训练过程弹性容错:由于部分因素导致任务异常或可预见问题如 Spot 回收事件预示下的整体任务的容错,避免因为少部分 Worker 失败而直接导致的整个任务的失败;
- 训练资源弹性伸缩:可以根据任务需要或者问题处理的判断来动态变更任务训练 Worker 的资源配置以达到一个更合理的任务 Worker 资源配比。
弹性分布式训练能够很好地解决分布式训练在成本、资源利用率和容错等方面的问题。而弹性训练的能力带来的意义,大概也可以总结为三点:
- 大规模分布式训练容错,有效提升训练任务运行的成功率;
- 提升集群算力利用率,充分利用弹性来协调在离线任务的资源分配;
- 降低任务训练成本,使用可被抢占或稳定性稍差但成本更低的实例来进行训练从而整体层面降低成本。
实现弹性分布式训练需要面对如下挑战:
- 通信和同步挑战
- 数据管理和分发挑战
- 容错和恢复挑战
- 系统架构和实现挑战:与云原生架构的兼容性;分布式系统复杂性
- 调度和资源管理的复杂性
弹性分布式训练解决了机器学习系统中分布式计算以及调度的问题。但是,还需要在算法层面利用并行策略解决大规模模型的分布式训练逻辑。 本文重点关注 Pytorch 在分布式弹性计算方面的工作。
pytorch 分布式训练
pytorch目前是 ML/LLM 领域最流行的机器学习框架之一,pytorch在分布式训练方面做了很多工作,核心代码是:torch.distributed package
PyTorch distribute package包括一组并行模块、一个通信层以及用于启动和调试大型训练作业的基础设施。
- 并行模块提供了4种并行API:Distributed Data-Parallel(DDP)、Fully Sharded Data-Parallel(FSDP)、Tensor Parallel(TP)、Pipeline Parallel(PP)
- Pytorch分布式通信层(C10D)提供了集合通信API(all_reduce、all_gather等)和 P2P通信API:distributed_c10d.py
- torchrun: 启动脚本,它在本地和远程机器上运行分布式 PyTorch 程序
业界主流的 DeepSpeed 和 Megatron-LM 等LLM训练库 都是基于 pytorch 构建的。
Pytorch分布式通信层
torch.distributed 包提供了通信原语和Pytorch支持,用于在一台或多台机器上运行的多个计算节点之间实现多进程并行。其中,通信原语包括:
- 集合通信API:
all_reduce和all_gather - P2P通信API:例如send 和 isend
torch.distribute最优雅的特性是:能够基于不同的backend进行抽象和构建。torch.distributed支持三种内置的Backend:
- gloo:用于分布式CPU训练
- NCCL:支持CUDA,用于分布式GPU训练
- mpi:用于分布式CPU训练
同时,torch.distributed 也允许用户使用 C/CPP 实现和编译自己的集合通信库并将其作为新的后端调用。这种设计模式可以使 torch.distributed 完全独立于集合通信后端。
支持分布式训练
基于torch.distribute分布式通信能力,torch.nn.parallel.DistributedDataParallel()提供同步分布式训练作为 PyTorch 模型的包装器。
这与torch.multiprocessing package和torch.nn.DataParallel()提供的并行类型不同,因为它支持多台网络相通的机器,并且用户必须为每个进程明确启动主训练脚本的单独副本。
在单机同步情况下,torch.distributed 或 torch.nn.parallel.DistributedDataParallel() 包装器可能仍然比包括torch.nn.DataParallel()其他数据并行方法有优势:
- 每个进程都维护自己的优化器,并在每次迭代中执行完整的优化步骤。虽然这看起来是多余的,但由于梯度已经收集在一起并在各个进程之间平均,因此对于每个进程都是相同的,这意味着不需要参数广播步骤,从而减少了在节点之间传输张量所花费的时间。
- 每个进程都包含一个独立的 Python 解释器,从而消除了额外的解释器开销和“GIL 抖动”,这些开销和抖动是由单个 Python 进程驱动多个执行线程、模型副本或 GPU 造成的。这对于大量使用 Python 运行时的模型(包括具有循环层或许多小组件的模型)尤其重要。
通信原语实现c10d:distributed_c10d
c10d 是一个 client-server 的架构,其中的一个 agent 上会运行 c10d 的 TCPServer,它监听给定的端口,提供了 compareAndSet、add 等原语。它也可以被理解为一个简化的,提供 KV 接口的内存数据库,类似于 Redis。 有关 rendezvous 的同步,都是由各个 agent 通过一个中心化的 agent 上的 c10d TCPServer 完成的。 这样的实现在可用性上相比于 etcd 是有一定差距的,但是胜在易用性。用户如果使用 c10d,那么不再需要运维一个 etcd 集群。
c10d是C++实现的服务。代码地址为:git地址
class:
- Backend:backend的枚举类,可用的backend包括GLOO、NCCL、MPI、UCC以及其他注册的backend。
- BackendConfig:
通信操作:
- P2POp:构建P2P操作类型、通信缓存、peer rank、Process Group等
- all_gather等集合操作函数:
torch.distributed.elastic: 分布式 PyTorch 具有容错和弹性。
PyTorch Elastic Trainer (PET) 提供了一个框架,可以以容错和弹性的方式在分布式计算集群中方便地训练模型。PET 通过两种方式提供这些功能:
- 当 PyTorch 工作进程抛出某类可重试错误时,PET 会捕获该错误并重试训练过程。
- 只要工作进程的数量保持在启动作业时指定的范围内,新工作进程就可以随时离开或加入现有训练作业的进程池。当成员发生变化时,所有工作进程都会重新会合(re-rendezvous)以建立新的进程组,训练将从之前已知的正常状态恢复。
elastic提供了如下能力:
- torchrun (Elastic Launch)
- Elastic Agent
- Multiprocessing
- Error Propagation
- Rendezvous
- Expiration Timers
- Metrics
- Events
- Subprocess Handling
- Control Plane
torchrun
torch.distributed.launch功能:在每个训练节点上创建多个分布式训练进程。
elastic_launch:在container启动一个torchelastic agent
- launch-agent():根据
LaunchConfig配置初始化 LocalElasticAgent,并运行。
Multiprocessing
用于启动和管理由函数或二进制指定的工作子进程的n个副本。
对于函数,它使用torch.multiprocessing(或者 python multiprocessing)来spawn/fork工作进程。由 MultiprocessContext 负责管理
对于二进制文件,它使用 python subprocessing.Popen来创建工作进程。由 SubprocessContext 负责管理
start_processes方法的具体实现如下:
def start_processes(
name: str,
entrypoint: Union[Callable, str],
args: Dict[int, Tuple],
envs: Dict[int, Dict[str, str]],
logs_specs: LogsSpecs,
log_line_prefixes: Optional[Dict[int, str]] = None,
start_method: str = "spawn",
) -> PContext:
"""
Start ``n`` copies of ``entrypoint`` processes with the provided options.
``entrypoint`` is either a ``Callable`` (function) or a ``str`` (binary).
The number of copies is determined by the number of entries for ``args`` and
``envs`` arguments, which need to have the same key set.
"""
nprocs = len(args)
_validate_full_rank(args, nprocs, "args")
_validate_full_rank(envs, nprocs, "envs")
context: PContext
if isinstance(entrypoint, str):
context = SubprocessContext(
name=name,
entrypoint=entrypoint,
# ...
)
else:
context = MultiprocessContext(
name=name,
entrypoint=entrypoint,
# ...
)
try:
context.start()
return context
except Exception:
context.close()
raise
Elastic Agent
elastic agent 是 torchelastic 的控制面,是一个独立的进程,用于启动和管理Workers进程。其提供的能力:
- 使用分布式torch进行工作:workers使用必要的信息进行启动,可以轻松地调用
torch.distributed.init_process_group() - 容错:监控 workers,一旦发现 workers 故障或者异常,那么停止所有的workers并启动所有的workers
- 弹性:对成员变更作出反应,使用新的成员重启所有worker
PET使用 elastic-agent 来实现。每个job对应一个elastic-agent。每个agent负责管理一组Node本地的worker进程,
还负责与分配该Job的其他elastic agent协调进程组成员变更。如图:
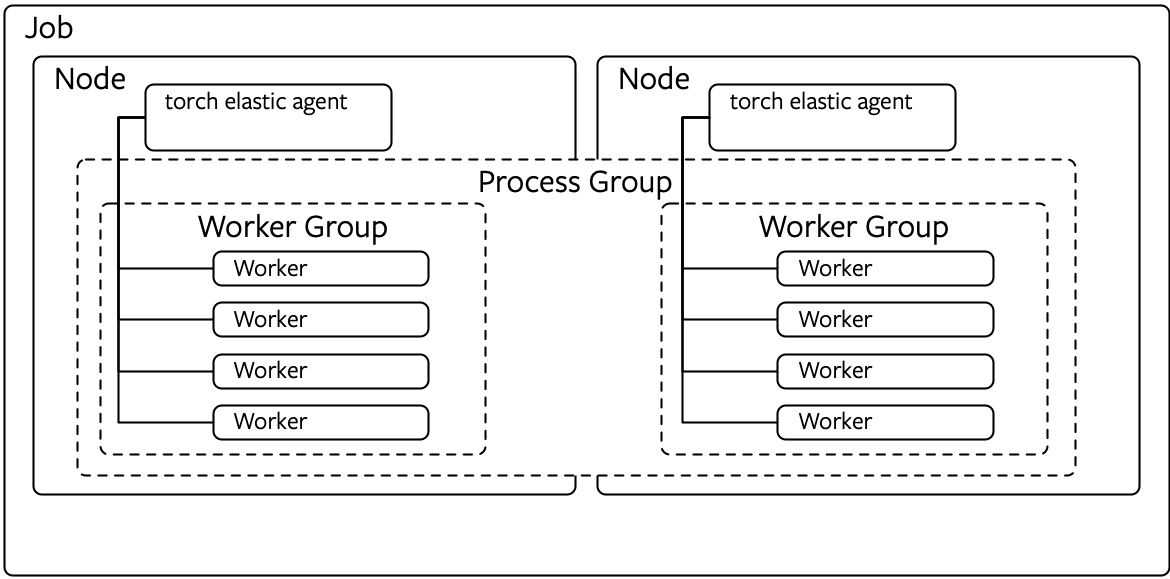
简单的agent是部署在每个node上,并与本地进程进行工作。更高级的agent能够启动和管理远程的workers。 agents是去中心化的,可以基于所管理的workers作出决策。或者可以进行协调,与其他agent(管理同一工作组的 worker)进行通信以做出集体决策。
不同的 elastic agent之间通过 rendezvous进行 Worker 之间的相互发现和对成员变动的同步。
与此同时,通过对 worker 进程的监控,来捕获训练过程中的失败。核心逻辑都在 LocalElasticAgent.run()方法中。
下图为agent管理一个本地组的Worker,如图:
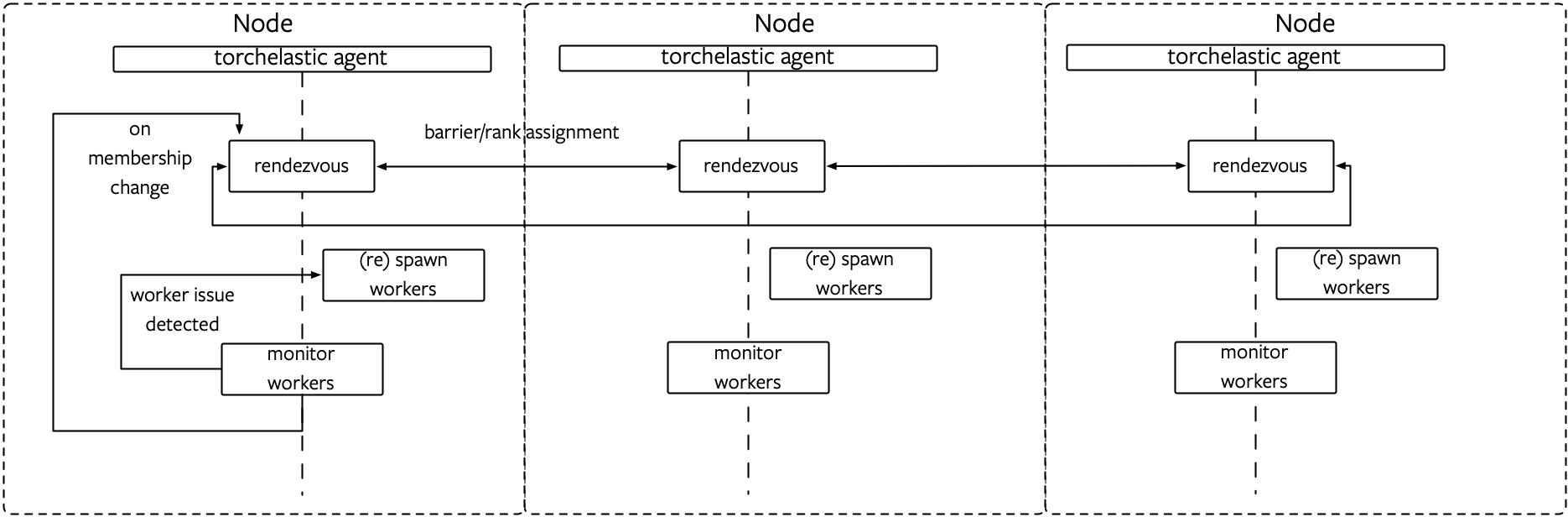
实现
基础的类:
- WorkerSpec:表示 Worker 的说明
- Worker:
- id(唯一标识)
- global_rank(全局排名,在re-rendezvous中不稳定的)
- role_rank:所有相同角色的worker中的排名
- world_size: 全部的worker数量
- role_world_size: 具有相同角色的worker数量
- WorkerState:一个worker group中所有Workers的变更状态作为一个单元;如果其中单个worker失败,整个集合认为失败
- WorkerGroup:Worker实例集合;定义了给定WorkerSpec对应的Worker实例集合,由ElasticAgent来管理。
_RoleInstanceInfo: agent用来与其他agent交换信息RunResult: worker执行的结果。RunResults遵循all-or-nothing策略,只有当agent管理的所有本地workers成功完成,整体运行才是成功的
Worker和WorkerSpec之间的关系是 对象和类之间的关系。
WorkerState是WorkerGroup的状态
Worker group状态状态机为:从INIT初始状态开始,然后变化为 HEALTHY或者UNHEALTHY状态,最终变成终止状态(SUCCESSED或者Failed)。
Worker group会被Agent中断,或者临时变成STOPPED状态。STOPPED状态的Worker不久会被Agent调度重启。
转变为STOPPED状态的worker有一些例子,比如:
- Worker group宕机,或者观测到不健康
- 检测到成员发生变更
ElasticAgent: 负责管理一个或多个worker进程的agent进程。
- worker进程认为是常规的分布式Pytorch脚本
- 当agent创建worker进程时,agent为worker提供了必要的信息来初始化一个torch worker group
agent-to-worker的部署拓扑和比率取决于agent的具体实现以及job分配偏好。例如,使用8个trainer(每个trainer对应一个GPU)在GPU运行分布式训练任务,可以是:
- 使用8个单GPU实例,一个实例上运行一个Agent,每个agent管理一个worker
- 使用 4 x 2 GPU实例,每个实例上运行一个agent,每个agent管理2个worker
- 使用 2 x 4 GPU实例,每个实例上运行一个agent,每个agent管理4个worker
- 使用 1 x 8 GPU实例,每个实例上运行一个agent,每个agent管理8个worker
SimpleElasticAgent 和 LocalElasticAgent 是 ElasticAgent 的实现
SimpleElasticAgent实现
SimpleElasticAgent:管理特定类型的worker角色的ElasticAgent
SimpleElasticAgent:
- WorkerGroup
- WorkerSpec
- RendezvousHandler
- WorkerSpec
- 默认实现的方法:
_assign_worker_ranks:判断工作进程正确的rank。_rendezvous(worker_group: WorkerGroup):由worker spec指定的workers执行会合run(role: str):根据 WorkerGroup的状态重启workers或者直接退出_initialize_workers(worker_group: WorkerGroup):启动新的workers_restart_workers(worker_group: WorkerGroup):重启(stops, rendezvous, start)工作组所有本地的worker
rank分配算法为:
- 每个agent将其配置(group_rank、group_world_size、num_workers)写入公共存储。
- rank 0 的代理从存储中读取所有 role_info 并确定每个agent的 worker ranks。
- 确定全局rank:workers的全局rank由其前面所有workers的 local_world_size 的累计和计算得出。出于效率原因,每个worker都分配有一个base_global_rank,使得其worker在 [base_global_rank、base_global_rank + local_world_size) 范围内。
- 确定role rank:role rank使用第 3 点中的算法确定,但rank是根据role名称计算的。
- rank 0 的agent将分配的rank写入存储。
- 每个agent从存储中读取分配的rank。
时间复杂度:每个worker O(1),rank0 O(n),overall O(n)
LocalElasticAgent实现
LocalElasticAgent:
- 在每台主机上部署,配置为创建n个workers;当使用GPU时,
n映射为主机上可用的GPU数量 - 本地agent不能与部署在其他host的agent进行通信,即使workers可以跨主机通信
- worker id被解析为本地进程。agent作为一个单元启动和停止所有的worker进程
实现的方法:
_start_workers(worker_group: WorkerGroup)_stop_workers(worker_group: WorkerGroup)_monitor_workers(worker_group: WorkerGroup)
Rendezvous:会合
在 Torch 分布式弹性上下文中,使用术语“会合”来指代将分布式同步原语与对等发现相结合的特定功能。
Torch Distributed Elastic 使用 Rendezvous 来聚集训练作业的参与者(即节点),以便他们都就相同的参与者列表和每个人的角色达成一致,并就何时开始/恢复训练做出一致的集体决定。
Torch 分布式弹性Rendezvous提供了以下关键功能:
Barrier(屏障):
执行会合的节点将全部阻塞,直到会合被视为完成 - 这种情况发生在至少min个节点都加入会合屏障(用于同一项工作)时。这也意味着屏障不一定是固定大小。
达到min节点数后还有一段额外的短暂等待时间:这是为了确保会合不会“太快”完成(这可能会排除大约同时尝试加入的其他节点)。
如果在屏障处聚集了max个节点,会合就会立即完成。
如果min节点数从未达到,还存在一个整体超时时间,这会导致会合失败 - 这是一个简单的故障保护,用于帮助释放部分分配的作业资源,以防资源管理器出现问题,并且意味着不可重试。
简而言之:如果节点数小于min,整体Rendezvous有默认的超时时间;最少等待min个节点加入Rendezvous屏障,然后等待短暂时间;如果节点数达到max,Rendezvous完成。
Exclusivity(独占性):
简单的分布式屏障是不够的,因为我们还需要确保在任何给定时间(对于给定作业)只存在一组节点。换句话说,新节点(即后加入的节点)不应该能够为同一作业形成一组并行的独立工作组。
Torch 分布式弹性 Rendezvous 确保如果一组节点已经完成会合(因此可能已经在训练),那么试图会合的其他“迟到”节点只会宣布自己在等待,并且必须等到(先前完成的)现有会合首先被销毁。
简而言之,后加入的节点只能等待 未来下一次的Rendezvous。
Consistency(一致性):
当Rendezvous完成后,所有成员将就job membership(工作成员)和每个人在其中的角色达成一致。此角色使用一个整数表示,称为等级(rank),介于 0 和 world size 之间。
请注意,rank是不稳定的,因为同一个节点可以在下一次(重新)Rendezvous时被分配不同的等级。
Fault-tolerance(容错性):
Torch 分布式弹性Rendezvous旨在容忍Rendezvous过程中的节点故障。如果在加入会合和完成会合之间进程崩溃(或失去网络连接等),则会自动与剩余健康节点重新会合。
节点在完成会合(或被其他节点观察到已经完成会合)后也可能失败- 这种情况将由 Torch Distributed Elastic train_loop处理(它也会触发重新会合)。
Shared key-value store(共享键值存储):
当Rendezvous完成时,将创建并返回一个共享的键值存储。此存储实现了一个torch.distributed.StoreAPI(请参阅 分布式通信文档)。
此存储仅由已完成会合的成员共享。它旨在供 Torch Distributed Elastic 用来交换 初始化作业控制和数据平面 所需的信息。
Waiting Worker and rendezvous Closing:
Torch 分布式弹性 Rendezvous handler 对象提供了额外的功能,从技术上讲,这些功能不属于 Rendezvous 过程的一部分:
-
查询有多少 workers 迟到,谁可以参加下一次 Rendezvous。
-
设置Rendezvous为关闭,以通知所有节点不再参与下一次Rendezvous。
DynamicRendezvousHandler:
Torch Distributed Elastic 提供了DynamicRendezvousHandler类,其实现上述描述的Rendezvous机制。它是一种后端无关的类型,需要在构造过程中指定特定 RendezvousBackend 实例。
Torch 分布式用户可以实现自己的后端类型,也可以使用 PyTorch 内置的以下实现之一:
- C10dRendezvousBackend: 使用 C10d store (by default TCPStore) 作为会合 backend. 使用C10d store的最大好处是 不需要第三方依赖(例如 etcd)来创建Rendezvous。
- EtcdRendezvousBackend: 取代旧的 EtcdRendezvousHandler class.
下图是:描述Rendezvous如何工作的状态图
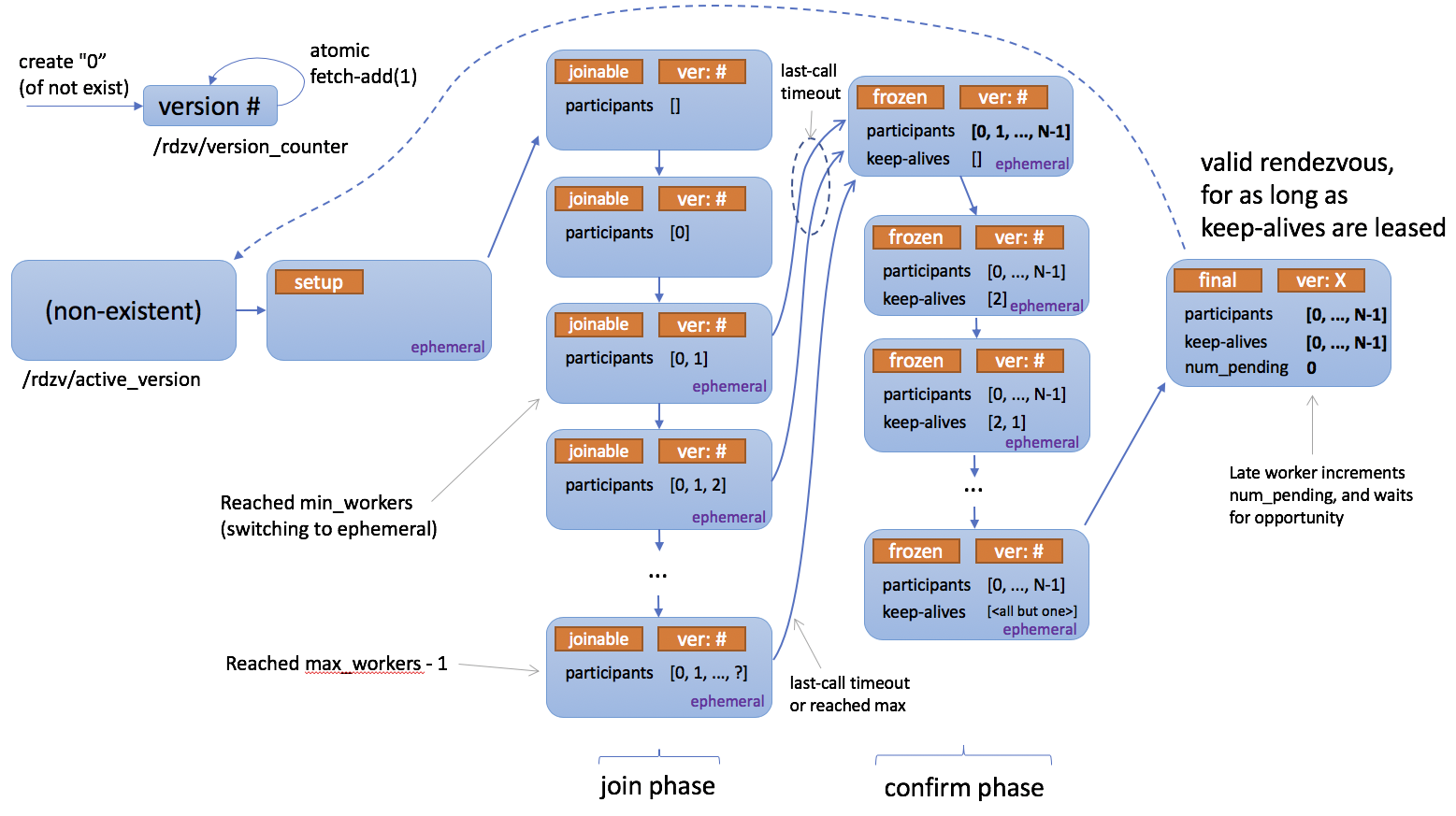
rendezvous实现
Rendezvous
- RendezvousStoreInfo:存储address和port,用来启动trainer分布式通信
- registry: 预先注册已经实现的RendezvousHandler(etcd, etcd-v2, c10d, static-tcp),
- RendezvousHandlerRegistry: 负责创建以及初始化 RendezvousHandler
- RendezvousHandler: 对于分布式torch使用者,无须实现;默认实现了C10d store,推荐使用
- RendezvousInfo:存储关于Rendezvous的信息
- RendezvousParameters:用于初始化RendezvousHandler的参数
- _create_c10d_handler:
- 创建c10d backend
- store: tcp/file store.真正的实现是用C++实现的
- 创建handler:统一由 DynamicRendezvousHandler 来创建
- NodeDesc
- RendezvousSettings
- _RendezvousStateHolder
- _RendezvousOpExecutor: _DistributedRendezvousOpExecutor
- 创建c10d backend
- _create_etcd_handler
- _create_etcd_v2_handler
- _create_static_handler
实现:
- DynamicRendezvousHandler:表示在一组节点上设置Rendezvous的handler。
- RendezvousBackend:C10d Backend;Etcd Backend
- EtcdRendezvousHandler:
- StaticTCPRendezvous:基于TCPStore的wrapper,静态会合
DynamicRendezvousHandler是Rendezvous的核心实现,支持两种Backend
属性:
_NodeDescStore:PrefixStore(插入store的每个key添加一个prefix),store支持TCPStore、FileStore、HashStore三种存储_RendezvousStateHolder:与其他节点通过backend同步会合状态RendezvousSettings:Rendezvous 的设置_RendezvousOpExecutor:执行 Rendezvous 操作;具体实现为_DistributedRendezvousOpExecutor:- run方法:在状态机里执行操作,操作可以将会合状态迁移到另一个状态
_RendezvousOpExecutor状态机具体的状态包括:
class _Action(Enum):
"""Specifies the possible actions based on the state of the rendezvous."""
KEEP_ALIVE = 1
ADD_TO_PARTICIPANTS = 2
ADD_TO_WAIT_LIST = 3
ADD_TO_REDUNDANCY_LIST = 4
REMOVE_FROM_PARTICIPANTS = 5
REMOVE_FROM_WAIT_LIST = 6
REMOVE_FROM_REDUNDANCY_LIST = 7
MARK_RENDEZVOUS_COMPLETE = 8
MARK_RENDEZVOUS_CLOSED = 9
SYNC = 10
ERROR_CLOSED = 11
ERROR_TIMEOUT = 12
FINISH = 13
RendezvousHandler接口定义:
class RendezvousHandler(ABC):
"""Main rendezvous interface.
"""
@abstractmethod
def next_rendezvous(self) -> RendezvousInfo:
"""Main entry-point into the rendezvous barrier.
Blocks until the rendezvous is complete and the current process is
included in the formed worker group, or a timeout occurs, or the
rendezvous was marked closed.
Returns:
Instance of :py:class:`RendezvousInfo`.
Raises:
RendezvousClosedError:
The rendezvous is closed.
RendezvousConnectionError:
The connection to the rendezvous backend has failed.
RendezvousStateError:
The rendezvous state is corrupt.
RendezvousTimeoutError:
The rendezvous did not complete on time.
"""
# ...省略一些接口定义
@abstractmethod
def set_closed(self):
"""Mark the rendezvous as closed."""
next_rendezvous()方法的核心逻辑为:
- 停止heartbeat
- 获取deadline
- 由
_RendezvousOpExecutor执行_RendezvousExitOp() - 由
_RendezvousOpExecutor执行_RendezvousJoinOp() - 开始heartbeats
- 获取store、rank、world_size,初始化 RendezvousInfo 并返回
整体的设计合理,python业务逻辑较为轻量,底层的C10d实现并未进行详细分析。